20 道 Java 高頻面試題 - 題解
作者丨安琪拉的博客
來源丨安琪拉的博客
這裏是更新的 20 道題題解:
-
自我介紹一下
重點介紹自己最滿意的技術,言簡意賅的說最近一段工作經歷和項目,突出項目的貢獻。
2. 項目中用到的技術棧介紹一下
3. 項目中做的認爲比較滿意的部分講一講?
提前梳理好,重點介紹自己熟悉和深入研究過的,特別注意,選擇介紹在項目中有真實應用場景的技術,有實際落地的案例是加分項。有的人可能學了很多東西,但是具體一問都沒動手實踐過。
- 如果這個技術方案讓你重新設計,你怎麼做?
這個需要在平時工作中就想好,不浮在表面,思考要有深度,你是否對自己負責的系統做過完整的梳理,把整個鏈路、模塊之間的關係都摸清楚了。例如面試官可能會問你,你的系統能承受多大的 QPS、一次業務請求在系統中的完整鏈路,某個模塊的實現邏輯,讓你重新設計有沒有可能做到更好。
- Java 集合類都有哪些?平常用到哪些?
安琪拉畫了如下這張圖,我建議大家有時間看看 java.util 的源碼,可以自己動手畫一畫,印象會更深刻。
上面這個圖梳理一下,爲了方便對照上圖看,圖都放在最後
-
Java 中的集合類可以分爲兩大類:一類是實現 [Map 接口];另一類是實現 [Collection 接口]。
實現 Collection 接口的分爲 List 和 Set,所以 Java 集合類是由 Map、List、Set 構成。
-
Map 提供了鍵(key)值(value)對,定義了映射關係,如 圖 5.1 所示,這個接口定義了 Map 需要的一些基本的方法,例如:size()、get()、put()。
AbstractMap 是抽象類(接口和抽象類統一用虛線框),實現了一些基礎的操作。類定義如下:
public abstract class AbstractMap<K,V> implements Map<K,V>K 是 key 的泛型,V 是 value 的泛型知識點: 經常面試被拿來比較的是 HashMap 和 HashTable。區別是 HashTable 是線程安全的,實現方式是 HashTable 會在一些需要操作 hash 表的地方加鎖,具體方法就是在函數方法聲明上加了’synchronized‘ 關鍵字,例如:put 和 get 方法。
知識點: WeakHashMap 基於 WeakReference,
-
強引用,例如 Object angela = new Object(), angela 就是強引用,對象只要還被引用,直到內存不足也不會被回收。
-
WeakReference,當一個對象被 WeakReference 引用, 而沒有任何其他 strong reference 指向的時候, 如果 GC 運行, 那麼這個對象就會被回收;
-
SoftReference 和 WeakReference 一樣, 但被 GC 回收的時候需要多一個條件: 當系統內存不足時纔會回收 SoftReference 引用的對象。
-
TreeMap 實現了 SortedMap(實際上實現的是 NavigableMap,NavigableMap 繼承了 SortedMap),底層數據結構是紅黑樹,存放的元素都是按照 key 來排序的,排序規則可以傳入
Comparator來定義。 -
WeakHashMap 有個特點,它裏面的元素隨時可能會變成 null,它是基於 WeakReference 實現,舉個例子:
WeakHashMap hashMap = new WeakHashMap(); for (int i = 0; ; i++) { //一直往裏面加數據, 內存會爆炸 hashMap.put(i, new String("angela")); //每隔一千次判斷一下有沒有對象被回收 if (i % 10000 == 0) { //遍歷一遍 for (int j = 0; j < i; j++) { // if (hashMap.get(j) == null) { System.out.println("key爲" + j + "的對象已經爲null, GC會回收"); return; } } }打印:
key爲54808的對象已經爲null, GC會回收 -
HashMap 想必大家都知道是面試的重中之重,基本常規面試很容易被問
-
List 下有 ArrayList 和 LinkedList,Vector,Stack。
知識點: ArrayList 和 LinkedList 區別,
最大的區別: ArrayList 底層是基於數組的數據結構,LinkedList 基於鏈表的數據結構;
-
Vector 和 ArrayList 區別是 Vector 是線程安全的。
-
Stack 是棧,繼承自 Vector,和 Vector 一樣,基礎數據結構都是數組,Stack 使用數組實現先進後出,基本原理是 push: 向數組尾部追加元素,pop 是讓數組尾部置空,設置元素爲 null。
想詳細瞭解 Stack,可以參考我寫的這篇: Java 知識體系 - Java 集合棧
-
數組和鏈表區別很明顯,數組隨機訪問速度快,鏈表查找需要從表頭開始找。理解什麼是隨機訪問,就是給定一個隨機的 index(下標),希望找到元素,數組直接 array[index] 訪問,時間複雜度 0(1), 鏈表是 O(n),因爲鏈表需要從頭開始找。
-
新增和刪除操作 add 和 remove,LinkedList 比較佔優勢,因爲 ArrayList 要移動數據。
-
Set 下有 HashSet、TreeSet。Set 最大的特點是 key 是唯一的,不允許重複。
HashSet 也是基於 HashMap 實現的,只不過 value 是固定值。
TreeSet 是基於 TreeMap 實現,當然初始化的時候也可以指定基於自定義的 NavigableMap 實現。存放的元素是基於 key 排序好的。
所以實際上搞懂 HashMap 和 TreeMap,這二個 Set 基本也清楚了。
- ArrayList 和 LinkedList 區別?
最大的區別: ArrayList 底層是基於動態數組的數據結構,LinkedList 基於鏈表的數據結構;
-
數組和鏈表區別很明顯,數組隨機訪問速度快,鏈表查找需要從表頭開始找。理解什麼是隨機訪問,就是給定一個隨機的 index(下標),希望找到元素,數組直接 array[index] 訪問,時間複雜度 0(1), 鏈表是 O(n)。
-
新增和刪除操作 add 和 remove,LinkedList 比較佔優勢,因爲 ArrayList 要移動數據。
- HashMap 實現的數據結構和擴容過程?
數據結構是數據 + 鏈表
- ArrayList 和 LinkedList 區別?你平常怎麼選擇?
-
比較多的隨機訪問,比如用下標 index 訪問集合,用 ArrayList;
-
如果有比較多的在集合中間插入和刪除,用 LinkedList,因爲 ArrayList 中間每次插入、刪除需要移動數組元素。
- 異常類都有哪些?Exception 和 Error 什麼區別?
-
Error 是錯誤,對於所有的編譯時期的錯誤以及系統錯誤都是通過 Error 拋出的。這些錯誤表示故障發生於虛擬機自身、或者發生在虛擬機試圖執行應用時,如 Java 虛擬機運行錯誤(Virtual MachineError)、類定義錯誤(NoClassDefFoundError)等。這些錯誤是不可查的,因爲它們在應用程序的控制和處理能力之 外,而且絕大多數是程序運行時不允許出現的狀況。對於設計合理的應用程序來說,即使確實發生了錯誤,本質上也不應該試圖去處理它所引起的異常狀況。在 Java 中,錯誤通過 Error 的子類描述。
-
Exception 規定的異常是程序本身可以處理的異常。異常和錯誤的區別是,異常是可以被處理的,而錯誤是沒法處理的。其中 Exception 又有二類:
-
Checked Exception
可檢查的異常,這是編碼時非常常用的,所有 checked exception 都是需要在代碼中處理的。它們的發生是可以預測的,正常的一種情況,可以合理的處理。比如 IOException,或者一些自定義的異常。除了 RuntimeException 及其子類以外,都是 checked exception
-
Unchecked Exception
RuntimeException 及其子類都是 unchecked exception。比如 NPE 空指針異常,除數爲 0 的算數異常 ArithmeticException 等等,這種異常是運行時發生,無法預先捕捉處理的。Error 也是 unchecked exception,也是無法預先處理的。
- Synchronized 原理,鎖膨脹過程 ?
圖片
- synchronized 和 Reentrantlock 區別?
大家看下面這段,重在理解
兩者的共同點:
-
ReentrantLock 顯示的獲得、釋放鎖,synchronized 隱式獲得釋放鎖
-
ReentrantLock 可響應中斷、可輪迴,synchronized 是不可以響應中斷的,爲處理鎖的
不可用性提供了更高的靈活性 -
ReentrantLock 是 API 級別的,synchronized 是 JVM 級別的
二者的不同點:
1. ReentrantLock 可以實現公平鎖
2. ReentrantLock 通過 Condition 可以綁定多個條件
3. 底層實現不一樣, synchronized 是同步阻塞,使用的是悲觀併發策略,lock 是同步非阻塞,採用的是樂觀併發策略
4. Lock 是一個接口,而 synchronized 是 Java 中的關鍵字,synchronized 是內置的語言實現。
5. synchronized 在發生異常時,會自動釋放線程佔有的鎖,因此不會導致死鎖現象發生;而 Lock 在發生異常時,如果沒有主動通過 unLock() 去釋放鎖,則很可能造成死鎖現象,因此使用 Lock 時需要在 finally 塊中釋放鎖。
6. Lock 可以讓等待鎖的線程響應中斷,而 synchronized 卻不行,使用 synchronized 時,等待的線程會一直等待下去,不能夠響應中斷。通過 Lock 可以知道有沒有成功獲取鎖,而 synchronized 卻無法辦到。
7. Lock 可以提高多個線程進行讀操作的效率,既就是實現讀寫鎖等
作用:都用來協調多線程對共享資源的訪問
可重入性質:都是可重入鎖,同一線程可以多次獲得同一個鎖
鎖性質:都保證了可見性和互斥性
這道題總結解答出處:synchronized 和 ReentrantLock 區別是什麼?
-
線程池原理是怎樣的?
-
分佈式事務一致性怎麼實現?
這個大家可以優先看自己系統的實現。
我先來介紹一下分佈式事務一致性的需求背景,我們經常使用支付工具轉賬,比如以經典的小明給小紅轉賬 100 元爲例,如果是單機系統,我們可以用本機事務輕鬆解決,但是分佈式系統,轉賬可能是跨系統的調用,我們要保證數據的一致性就有些額外工作量了。
現在普遍互聯網分佈式系統都不會維護實習強一致性,而是做**最終一致性**,允許有短暫的不一致。
我這裏只介紹用的很普遍的事務消息,其他的比如二階段提交、本地消息表做數據一致性比對 & 補償都是實現一致性的方式。
事務消息發送步驟如下:
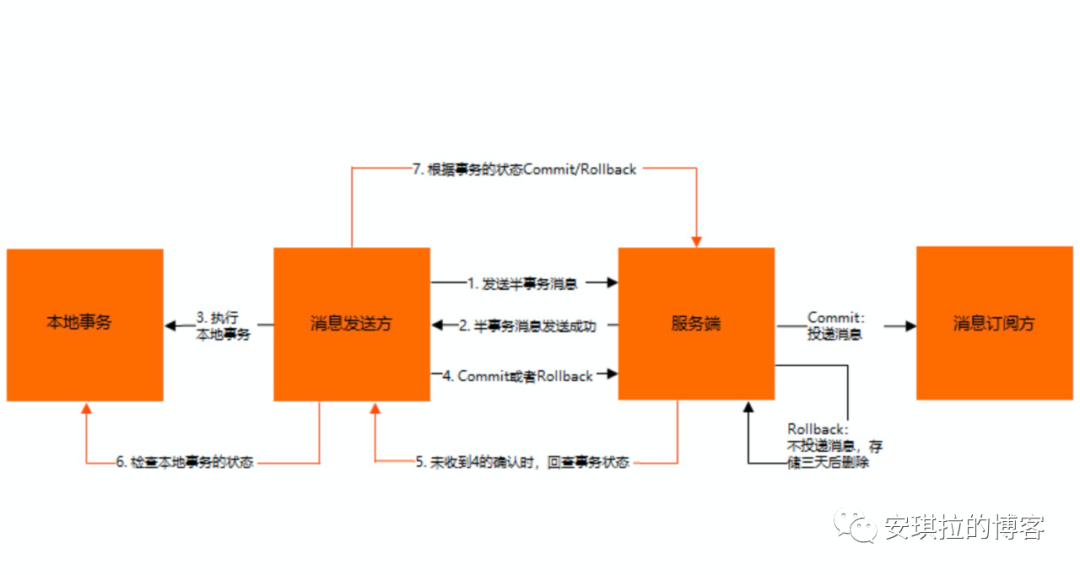
事務消息回查步驟如下:
以上內容參考: RocketMQ 事務消息-
在斷網或者是應用重啓的特殊情況下,上述步驟 4 提交的二次確認最終未到達服務端,經過固定時間後服務端將對該消息發起消息回查。
-
發送方收到消息回查後,需要檢查對應消息的本地事務執行的最終結果。
-
發送方根據檢查得到的本地事務的最終狀態再次提交二次確認,服務端仍按照步驟 4 對半事務消息進行操作。
-
發送方將半事務消息 (類似 prepare 消息),消息內容是將小紅賬號加 100 元,發送至消息隊列 RocketMQ 版服務端。
-
消息隊列 RocketMQ 版服務端將消息持久化成功之後,向發送方返回 Ack 確認消息已經發送成功,此時消息爲半事務消息。
-
發送方開始執行本地事務邏輯,講小明賬號扣減 100 塊。
-
發送方根據本地事務執行結果向服務端提交二次確認(100 塊扣成功則 Commit,100 塊扣失敗則發 Rollback),服務端收到 Commit 狀態則將半事務消息標記爲可投遞,訂閱方最終將收到該消息;服務端收到 Rollback 狀態則刪除半事務消息,訂閱方將不會接受該消息。
-
消息亂序遇到過嗎?怎麼解決的?
消息重複業務系統冪等解決,消息亂序,如果是業務系統,一般是 MQ 儘量保障同一用戶路由到同一消息分區,但這個只是儘量,一般消息亂序都是由下游消費方來處理,處理方法是消息中增加版本號、occurTime(業務時間發生時間) 來判斷消息的先後順序,然後做對應的業務邏輯,例如,同一業務流水號,從庫裏面的數據的版本號或 occurTime 和新消息的版本號和 occurTime 比較,版本號更大,時間更靠後的爲最新消息,可以做更新操作。
一般消息中間件都會遇到以下幾個問題:-
消息重複
-
消息併發
-
消息亂序
-
消息延遲
-
消息積壓
- ThreadLocal 用過嗎?實現機制?
發現很多博客關於 ThreadLocal 的說明寫錯了,ThreadLocal 不是維護了 key 爲 Thread 對象的 Map,而是 Thread 對象維護了一個 key 爲 ThreadLocal 對象的 Map。
參考之前寫的:一文了解 ThreadLocal 用法- wait、sleep 區別?
1、sleep 是線程中的方法,但是 wait 是 Object 中的方法。
2、sleep 方法不會釋放 lock,但是 wait 會釋放,而且會加入到等待隊列中。
3、sleep 方法不依賴於同步器 synchronized,但是 wait 需要依賴 synchronized 關鍵字。
4、sleep 不需要被喚醒(休眠之後退出阻塞),但是 wait 需要(不指定時間需要被別人中斷)。-
反射用過嗎?什麼原理?
-
動態代理瞭解嗎?
-
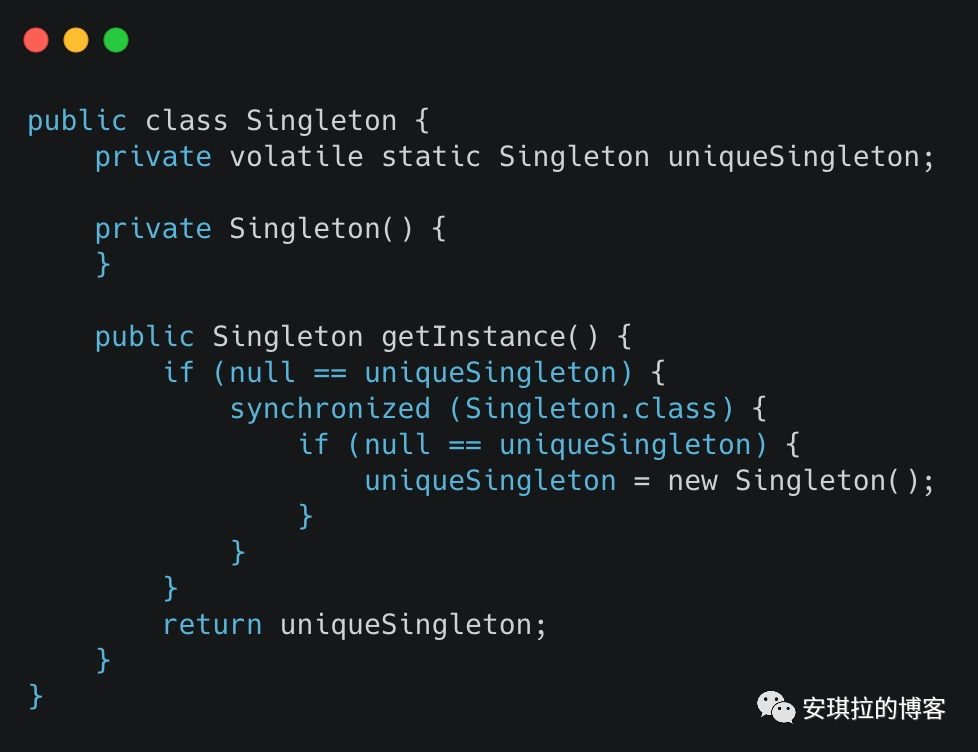
單例模式瞭解嗎?實現一個線程安全的單例模式?
單例模式(Singleton Pattern)是 Java 中最簡單的設計模式之一。這種類型的設計模式屬於創建型模式,它提供了一種創建對象的最佳方式。
這種模式涉及到一個單一的類,該類負責創建自己的對象,同時確保只有單個對象被創建。這個類提供了一種訪問其唯一的對象的方式,可以直接訪問,不需要實例化該類的對象。
**注意:**
實現代碼(只列舉雙重檢查鎖的寫法,其他寫法參考):
-
1、單例類只能有一個實例。
-
2、單例類必須自己創建自己的唯一實例。
-
3、單例類必須給所有其他對象提供這一實例。
- 無界隊列和有界隊列?
先說概念:
有界隊列
有界隊列:就是有固定大小的隊列。比如設定了固定大小的 LinkedBlockingQueue,又或者大小爲 0,只是在生產者和消費者中做中轉用的 SynchronousQueue。
無界隊列
無界隊列:指的是沒有設置固定大小的隊列。這些隊列的特點是可以直接入列,直到溢出。當然現實使用中,幾乎不會有到這麼大的容量(超過 Integer.MAX_VALUE),所以從使用者的體驗上,就相當於 “無界”。比如沒有設定固定大小的 LinkedBlockingQueue。
無界隊列的特性:所以無界隊列的特點就是可以一直入列,不存在隊列滿負荷的現象。這個特性,在我們自定義線程池的使用中非常容易出錯。而出錯的根本原因是對線程池內部原理的不瞭解。
使用無界隊列創建了一個線程池如下:
ExecutorService executor = new ThreadPoolExecutor(2, 4, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());這裏的隊列都指線程池使用的阻塞隊列 BlockingQueue 的實現,使用的最多的應該是 LinkedBlockingQueue,注意一般情況下要配置一下隊列大小,設置成有界隊列,否則 JVM 內存會被撐爆!
來一張隊列全體照
1. 常見的有界隊列
-
ArrayBlockingQueue: 基於數組實現的阻塞隊列;
-
LinkedBlockingQueue: 基於鏈表實現的阻塞隊列,該有界隊列不設置大小時就是 Integer.MAX_VALUE;
-
SynchronousQueue: 內部容量爲零,適用於元素數量少的場景,尤其特別適合做交換數據用,內部使用隊列來實現公平性的調度,使用棧來實現非公平的調度,在 Java6 時使用 CAS 代替了原來的鎖邏輯;
上面三個隊列的共性:
-
put 和 take 操作都是阻塞的
-
offer 和 poll 操作不是阻塞的,offer 操作時,若隊列滿了會返回 false,不會阻塞;poll 操作時,若隊列爲空會返回 null,不會阻塞;
-
並不是在所有場景下,非阻塞都是好的,阻塞代表着不佔用 CPU,在有些場景也是需要阻塞的,put 和 take 操作存在必有其存在的必然性;
ArrayBlockingQueue 與 LinkedBlockingQueue 對比:
-
ArrayBlockingQueue 實現簡單,表現穩定,添加和刪除操作使用同一個鎖,通常性能不如後者;
-
LinkedBlockingQueue 添加和刪除兩把鎖是分開的,所以競爭會小一些;
2. 常見的無界隊列
-
ConcurrentLinkedQueue:無鎖隊列,底層使用 CAS 操作,通常具有較高吞吐量,但是具有讀性能的不確定性,弱一致性——不存在如 ArrayList 等集合類的併發修改異常,通俗的說就是遍歷時修改不會拋異常;
-
PriorityBlockingQueue:具有優先級的阻塞隊列;
-
DelayedQueue:延時隊列,使用場景
-
- 緩存:清掉緩存中超時的緩存數據;
-
任務超時處理;
-
內部實現其實是採用帶時間的優先隊列,可重入鎖,優化阻塞通知的線程元素 leader
-
LinkedTransferQueue:簡單的說也是進行線程間數據交換的利器
無界隊列的共性:
-
put 操作永遠都不會阻塞,空間限制來源於系統資源的限制;
-
底層都使用 CAS 無鎖編程;
此題題解參數:
https://www.yuque.com/tiankongyiwusuoyouweihegeiwoanwei/kb/ud3nbr
本文由 Readfog 進行 AMP 轉碼,版權歸原作者所有。
來源:https://mp.weixin.qq.com/s/hmDOma_kTTH3xcdpKZuCzQ