hash 表在 go 語言中的實現
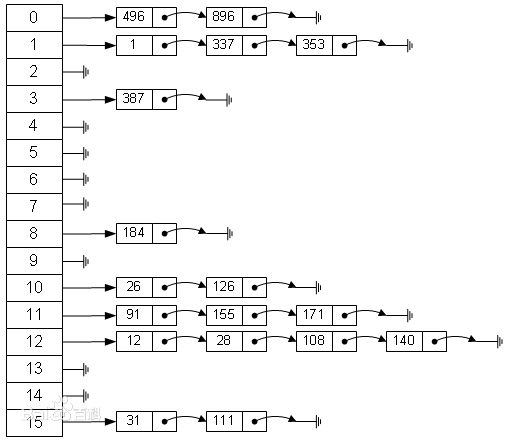
哈希表,是根據 key 值直接進行數據訪問的數據結構。即通過一個 hash 函數,將 key 轉換成換成數組的索引值,然後將 value 存儲在該數組的索引位置。如下圖:
{kind=link}
在 hash 表的結構設計中一般有 3 個關鍵問題需要解決:
- hash 衝突。即不同的 key 通過 hash 函數,會生成相同的 hash 值,即映射到相同的數組索引中。
- 空間浪費。即如果兩個 key 值,hash 之後,生成的索引值差距較大,就會對數組空間產生浪費。
- 擴容問題。即當現有的數組空間被填充滿時,如何存儲更多的鍵值。
hash 衝突的解決一般採用拉鍊法(當然還有開放地址法等)。即當有兩個不同的 key,經過 hash 函數,被 hash 到同一個位置的時候,不直接存儲在該索引下,而是將該值加到鏈表中,以免覆蓋第一個具有相同 hash 的 key 值。如下圖,假設 a 和 b 的 hash 值相同。
對於第二個問題,在 go 中是通過位操作來解決的。 即將 key 轉換成 hash 值後,並不直接用 hash 作爲索引,而是用 hash 和一個掩碼值(一般是和底層數組個數或其相關的一個值)進行取模或位操作後得到對應數組的索引值。
第三個問題是涉及到空間增長和數據遷移,即重新分配更大的空間,將原有的 key 重新 hash 到新的空間的索引位置上。
本文主要介紹在 go 中實現 hash 表的底層數據結構以及 hash 衝突的解決。。
map 數據結構
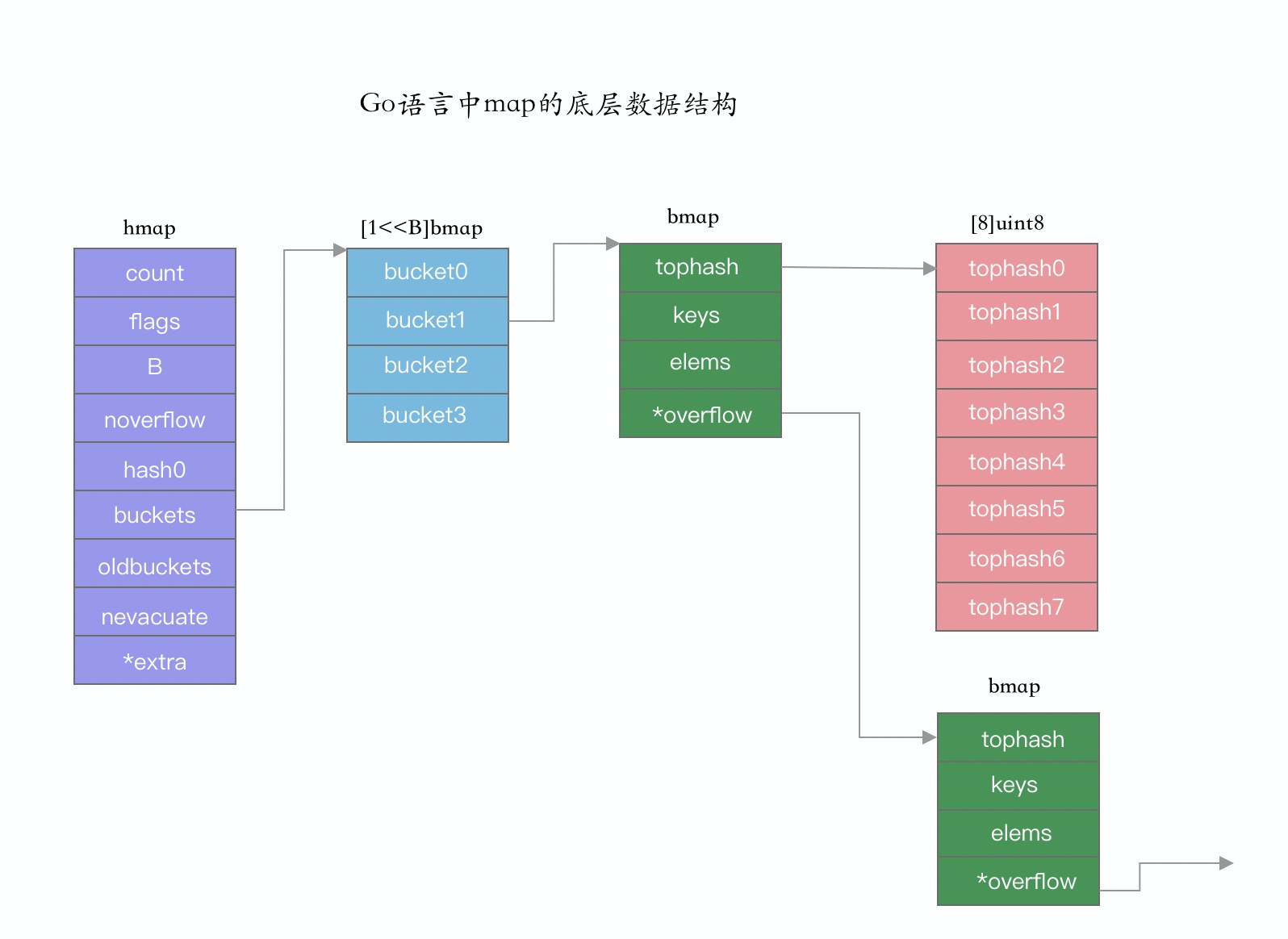
首先,整體來看下 go 中整體 map 的數據結構。如下圖:
{kind=link}
如上圖,我們得知在 map 的數據結構中主要包含 hmap,bmap 兩個結構體。
hmap 結構體
在 go 中,我們初始化或創建一個 map 時,實際上是創建了一個 hmap 結構體。hmap 的完整數據結構如下:
type hmap struct {
count int //map中的元素個數
flags uint8
B uint8 //log_2的對數,即buckets的個數爲2^B次方
noverflow uint16
hash0 uint32 //hash種子
buckets unsafe.Pointer //bucket數組指針
oldbuckets unsafe.Pointer //
nevacuate uintptr
extra *mapextra //溢出的buckets
}例如我們用如下語句創建一個 map 變量:
//創建一個容量爲10的map
m := make(map[string]int, 16)創建的 hmap 結構如下:
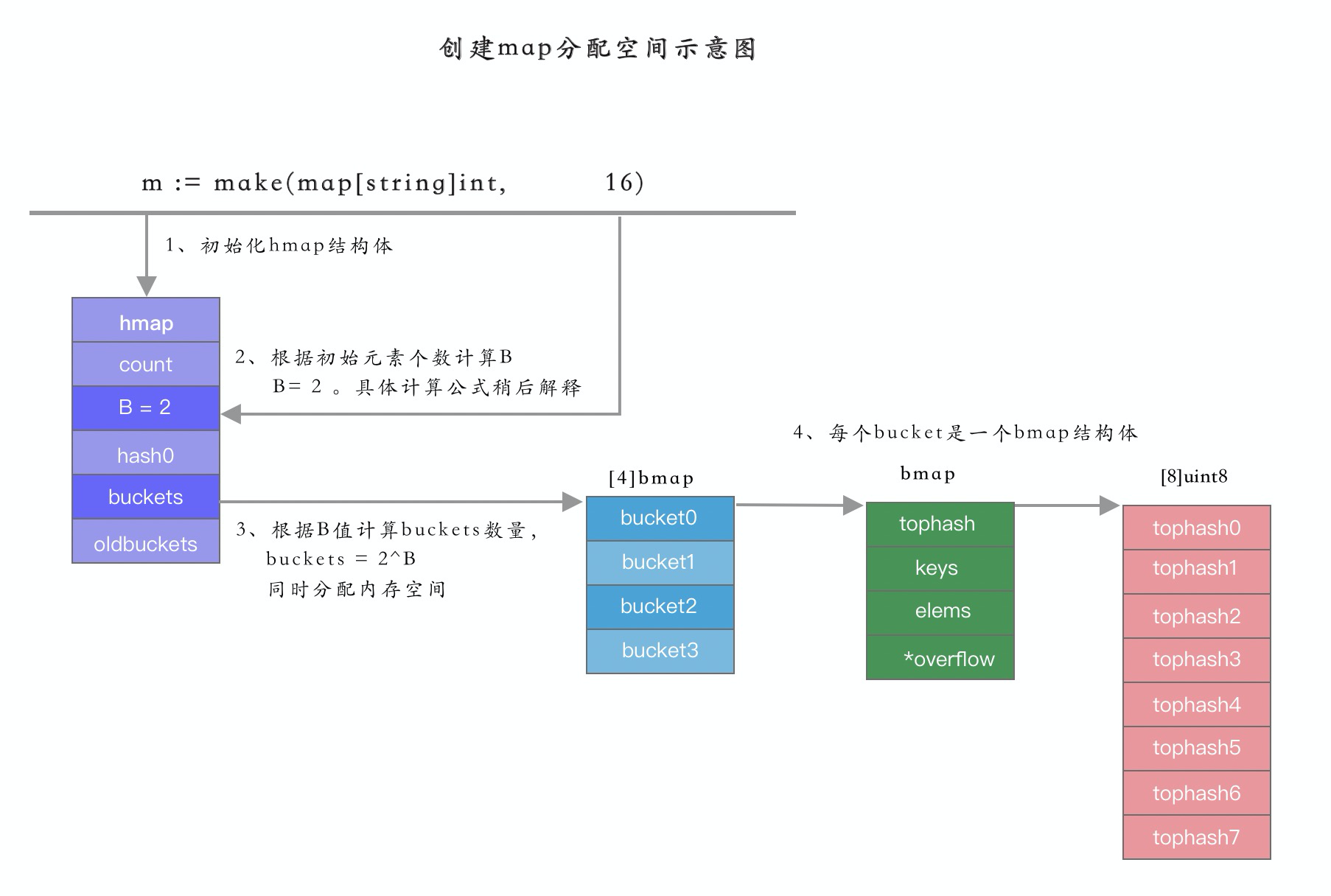{kind=link}
在 hmap 結構中,有以下幾個重要的字段:
- B :log_2 的對數,即 bucket 的個數 = 2^B 次方
- hash0:隨機數的種子。Go 運行時環境避免 hash 衝突使用。
- buckets:底層的 buckets 數組。
- extra:溢出的 buckets 數組。
數據結構中的 B 字段及其作用
根據上面的數據結構,我們可知,bucket 的個數 = 2^B 次方。那我們爲什麼需要這個 B 值呢? * 因爲我們需要用 B 值和 hash 值經過一定的運算後,得到 bucket 數組範圍內的索引 index *。
我們在用 map 的時候,key 是一個字符串,經過 hash 函數後轉換成數組的索引。但這個哈希後的數字不一定在 buckets 的數組範圍內。比如,我們的 buckets 數組個數是 8 個,一個 key 經過哈希函數轉換成的哈希值是 1378,那這個哈希值就不能直接作爲 buckets 數組的索引來存儲該 value。而且,我們也不能直接擴展該數組的空間來存儲該值,這樣將會浪費太多的空間。
所以,我們需要 B 和 hash 進行按位與操作,以此將 hash 值落到 bucket 數組的範圍之內。在 go 中代碼實現如下:
index := hash & (1 << B - 1)buckets
buckets 是 map 結構中的底層存儲結構,buckets 本質上一個 bmap 類型的數組,即每個 bucket 指向一個 bmap 結構體。數組大小由 B 字段值決定。
type bmap struct {
tophash [8]uint8 //容量爲8的數組,存儲hash值的高位
keys [8]keyType //該字段是在運行時階段自動加入的,在源碼中並沒有。
values [8]valueType //該字段是在運行時階段自動加入的,在源碼中並沒有。
}在 bmap 結構體中,tophash 是一個固定容量的數組。值得注意的是 keys 和 values 的存儲結構。key-value 的存儲並不是我們常見的 key-value/key-value 存儲,而是以 key0/key1/key2/.../key7/value0/value1/.../value7 格式存儲的。即先存 8 個 key,再存 8 個 value。這主要是考慮在內存對齊方面,可以避免浪費內存。
賦值操作
map 的賦值操作如下:
m['apple'] = 'mac'賦值操作的目標,是將 apple 經過 hash 之後,找到對應的 bucket,並存儲到 bmap 結構體中。
計算步驟如下: 1、根據 key 生成 hash 值 2、根據 hash 和 B 計算 bucket 的索引 3、根據 bucket 索引和 bucketsize 計算得到 buckets 數組的起始地址 4、計算 hash 的高位值 top 5、在 tophash 數組中依次該 tophash 值是否存在,如果存在,並且 key 和存儲的 key 相等,則更新該 key/value。如果不存在,則從 tophash 數組查找第一個空位置,保存該 tophash 和 key/value
場景一:tophash 數組未滿,且 k 值不存在時,則查找空閒空間,直接賦值
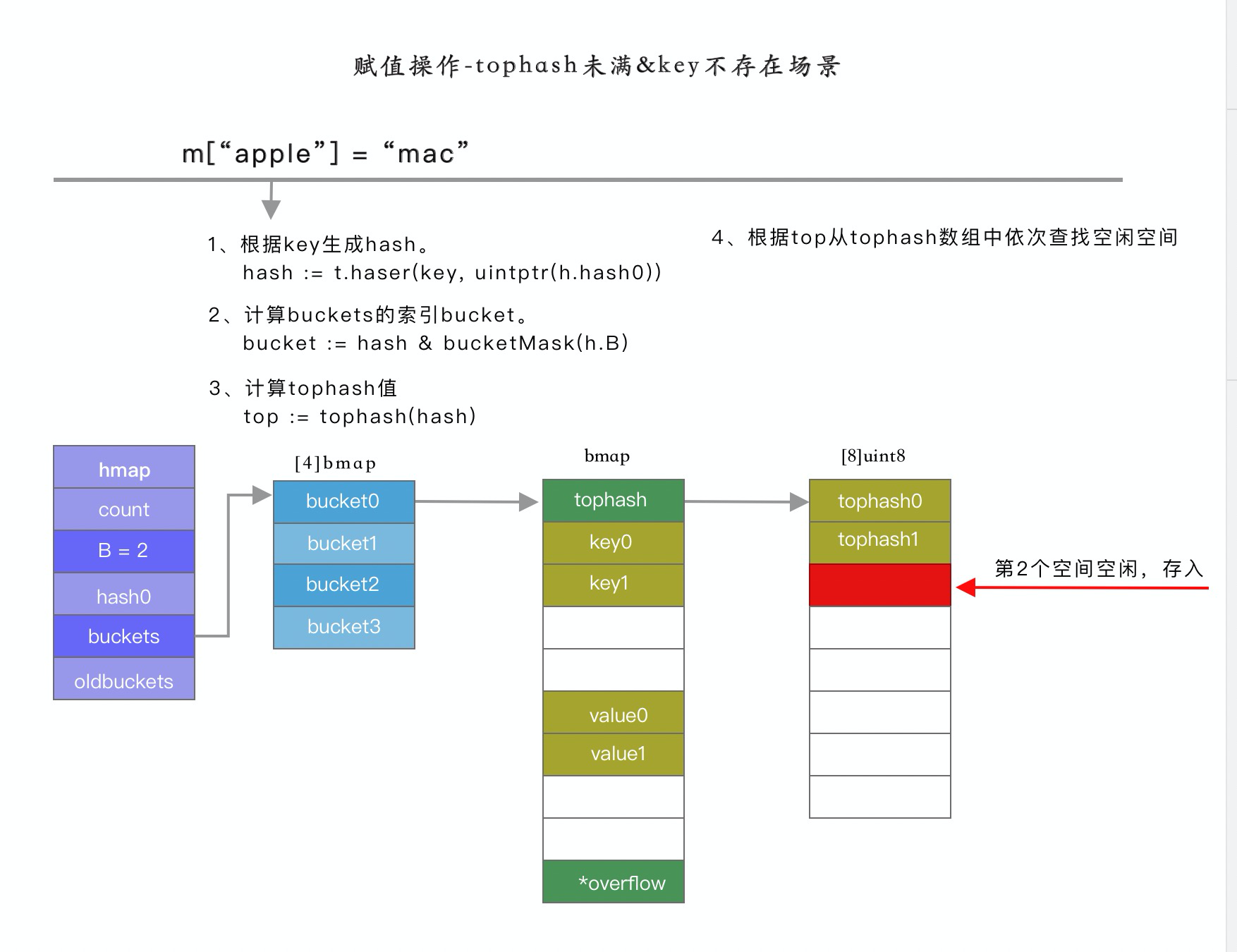{kind=link}
場景二:tophash 數組未滿,且 k 值已經存在,則更新該 k
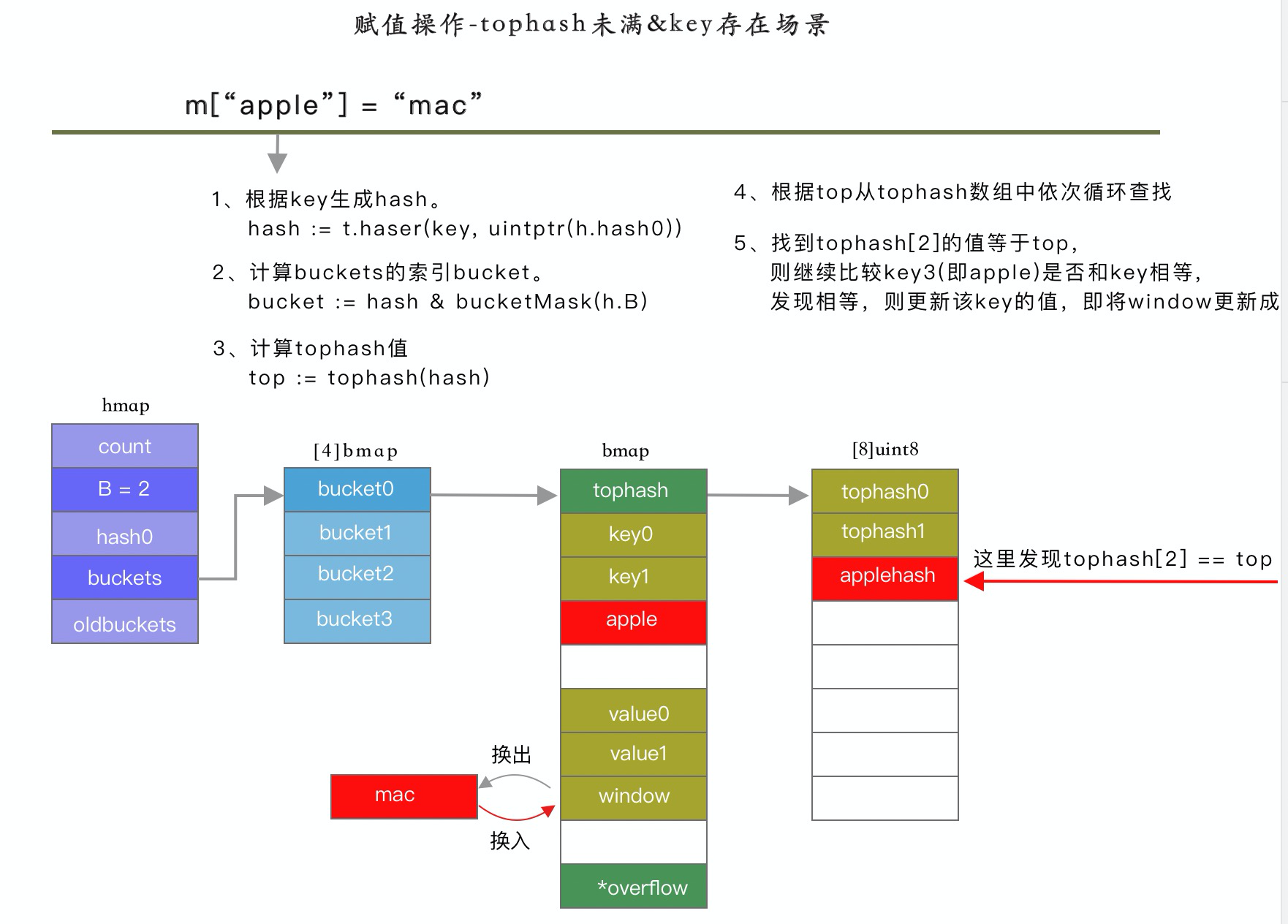{kind=link}
場景三:tophash 數組已滿,且 k 值不在當前的 bucket 的 tophash 中,則從 bmap 結構體中的 buoverflowt 中查找,並做更新或新增
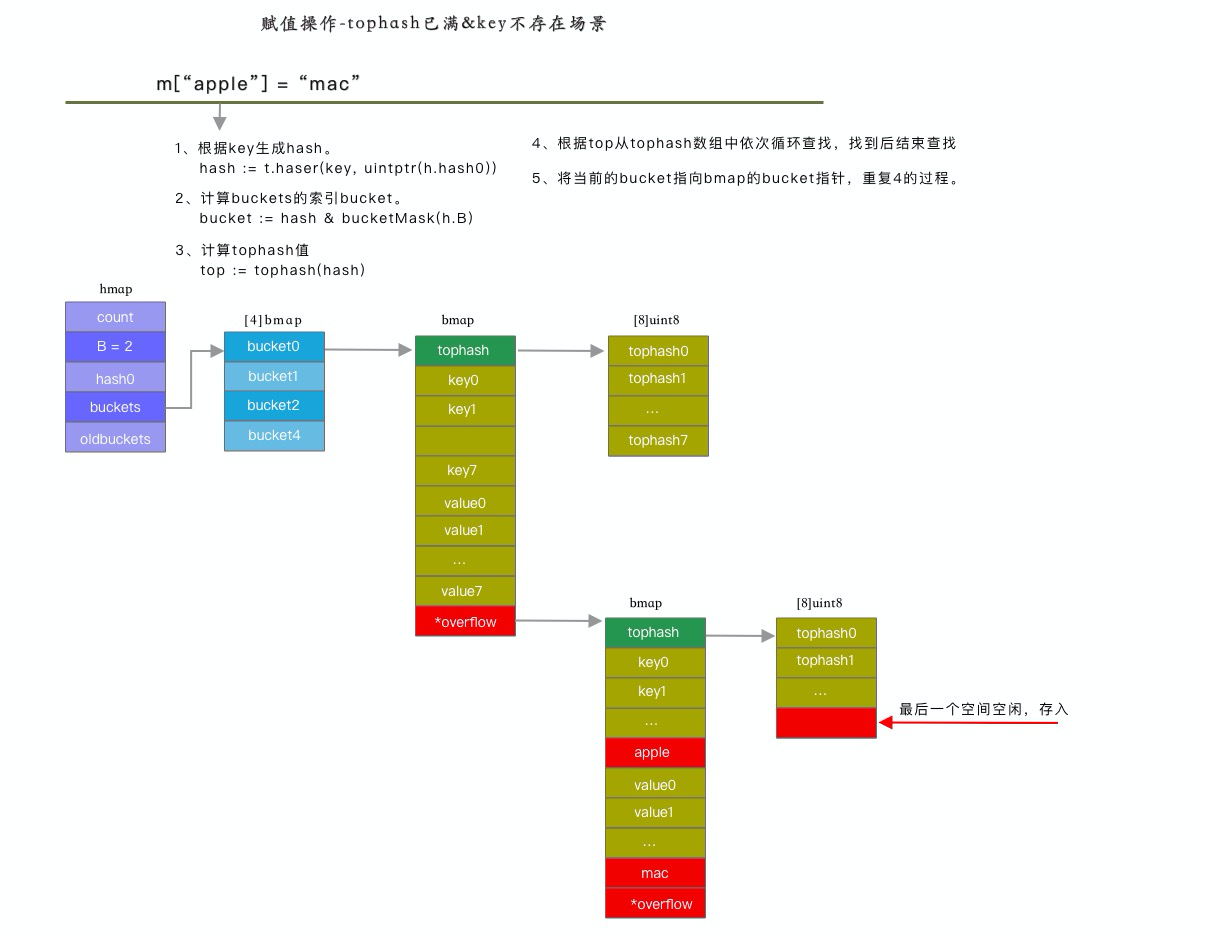{kind=link}
hash 衝突
由上面的賦值操作可知,當遇到 hash 衝突的時候,go 的解決方法是先在 tophash 的數組中查找空閒的位置,如果有空閒的位置則存入。如果沒有空閒位置,則在 bmap 的 overflow 指針指向的 bucket 中的 tophash 中繼續查,依次循環,直到找不等於該 key 的空閒位置,依次循環,直到從 tophash 中找到一個空閒位置爲止。
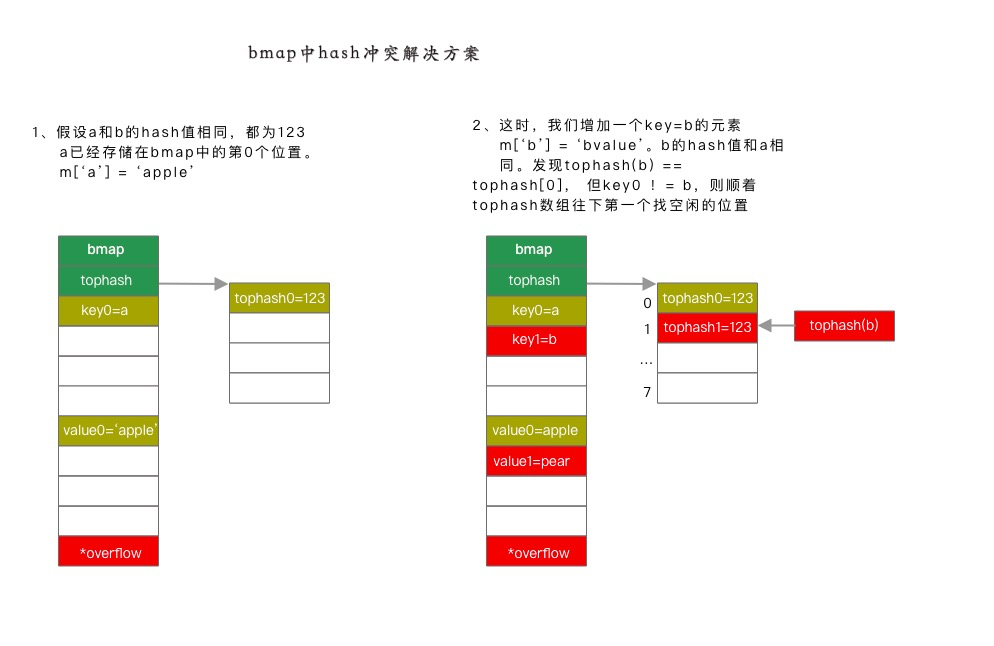{kind=link}
本文由 Readfog 進行 AMP 轉碼,版權歸原作者所有。
來源:https://gocn.vip/topics/11937